Professorship for High Performance Computing
Overview
![]()
The research activities of the HPC professorship are located at the interface between numerical applications and modern parallel, heterogeneous high-performance computers.
The application focus is on the development and implementation of hardware- and energy-efficient numerical methods and application programs. The foundation of all activities is a structured performance engineering (PE) process based on analytic performance models. Such models describe the interaction between software and hardware and are thus able to systematically identify efficient implementation, optimization and parallelization strategies. The PE process is applied to stencil-based schemes as well as basic operations and eigenvalue solvers for large sparse problems.
In the computer science-oriented research focus, performance models, PE methods and easy-to-use open source tools are developed that support the process of performance engineering and performance modeling on the compute node level. We focus on the continuous development of the ECM performance model and the LIKWID tool collection.
In teaching and training, the working group consistently relies on a model-based approach to teach optimization and parallelization techniques. The courses are integrated into the computer science and computational engineering curriculum at FAU. Furthermore, the group offers an internationally successful tutorial program on performance engineering and hybrid programming.
Prof. Wellein leads the HPC group at Erlangen Regional Computing Center (RRZE) and is the spokesman of the Competence Network for Scientific High Performance Computing in Bavaria (KONWIHR).
People
Prof. Gerhard Wellein

Dr. Jan Eitzinger

You can find an overview of the complete HPC group staff here.
Research topics
Hardware-efficient building blocks for sparse linear algebra and stencil solvers
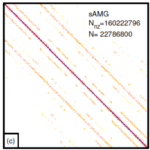
The solution of large, sparsely populated systems of equations and eigenvalue problems is typically done by iterative methods. This research area deals with the efficient implementation, optimization and parallelization of the most important basic building blocks of such iterative solvers. The focus is on the multiplication of a large sparse matrix with one or more vector(s) (SpMV). Both matrix-free representations for regular matrices, such as those occurring in the discretization of partial differential equations (“stencils”), and the generic case of a general SpMV with a stored matrix are considered. Our work on the development and implementation of optimized building blocks for SpMV-based solvers includes hardware-efficient algorithms, data access optimizations (spatial and temporal blocking), and efficient and portable data structures. Our structured performance engineering process is employed in this context.
Performance Engineering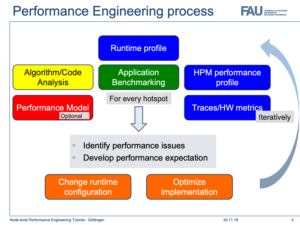
Performance Engineering (PE) is a structured, model-based process for the structured optimization and parallelization of basic operations, algorithms and application codes for modern compute architectures. The process is divided into analysis, modeling and optimization phases, which are iterated for each homogeneous code section until an optimal or satisfactory performance is achieved. During the analysis, the first step is to develop a hypothesis about which aspect of the architecture (bottleneck) limits the execution speed of the software. The qualitative identification of typical bottlenecks can be done with so-called application-independent performance patterns. A concrete performance pattern is described by a set of observable runtime characteristics. Using suitable performance models, the interaction of the application with the given hardware architecture is then described analytically and quantitatively.
The model thus indicates the maximum expected performance and potential runtime improvements through appropriate modifications. If the model predictions cannot be validated by measurements, the underlying model assumptions are revisited and refined or adjusted if necessary. Based on the model, optimizations can be planned and their performance gain be assessed a-priori. The PE approach is not limited to standard microprocessor architectures and can also be used for projections to future computer architectures. The main focus of the group is on the computational node, where analytic performance models such as the Roofline model or the Execution Cache Memory (ECM) model are used.
Performance Models
Performance models describe the interaction between application and hardware, forming the basis for a profound understanding of the runtime behavior of an application. The group pursues an analytic approach, the essential components of which are application models and machine models. These components are initially created independently, but their combination and interaction finally provide insights about the bottlenecks and the expected performance. Especially the creation of accurate machine models requires a profound microarchitecture analysis. The execution cache memory (ECM), which was developed by the group, allows predictions of single-core performance as well as scaling within a multi-core processor or compute node. In combination with analytic models of electrical power consumption, it can also be used to derive estimates for the energy consumption of an application. The ECM model is a generalization of the well-known Roofline model.
Performance Tools

The group develops, validates and maintains simple open source tools, which support performance analysis, the creation of performance models and the performance engineering process on the compute node level.
The well-known tool collection LIKWID (http://tiny.cc/LIKWID) comprises various tools for the controlled execution of applications on modern compute nodes with complex topologies and adaptive runtime parameters. By measuring suitable hardware metrics LIKWID enables a detailed analysis of the hardware usage of application programs and is thus pivotal for the validation of performance models and identification of performance patterns. The support for derived metrics such as attained main memory bandwidth requires a continuous adaptation and validation of this tool to new computer architectures.
The automatic generation of Roofline and ECM models for simple kernels is the purpose of the Kerncraft Tool (http://tiny.cc/kerncraft). An important component of Kerncraft is the OSACA tool (Open Source Architecture Code Analyzer), which is responsible for the single core analysis and runtime prediction of an existing assembly code (http://tiny.cc/OSACA). For all the tools mentioned above, we aim to support as many relevant hardware architectures as possible (Intel/AMD x86, ARM-based processors, IBM Power, NVIDIA GPU).
Based on LIKWID and the existing experience in performance analysis, the group is also pushing forward work on job-specific performance monitoring. The goal is to develop web-based administrative tools such as ClusterCockpit (http://tiny.cc/ClusterCockpit), which will make it much easier for users and administrators to identify bottlenecks in cluster jobs. ClusterCockpit is currently being tested at RRZE and other centers.
Selected publications
- J. Laukemann, J. Hammer, G. Hager, and G. Wellein: Automatic Throughput and Critical Path Analysis of x86 and ARM Assembly Kernels. 10th IEEE/ACM Workshop on Performance Modeling, Benchmarking and Simulation of High Performance Computer Systems (PMBS19), Denver, CO, USA. PMBS19 Best Late-Breaking Paper Award. Preprint: arXiv:1910.00214
- D. Ernst, G. Hager, J. Thies, and G. Wellein: Performance Engineering for a Tall & Skinny Matrix Multiplication Kernel on GPUs. Accepted for PPAM’2019, the 13th International Conference on Parallel Processing and Applied Mathematics, September 8-11, 2019, Białystok, Poland. PPAM 2019 Best Paper Award. Preprint: arXiv:1905.03136
- J. Hofmann, G. Hager, and D. Fey: On the accuracy and usefulness of analytic energy models for contemporary multicore processors. In: R. Yokota, M. Weiland, D. Keyes, and C. Trinitis (eds.): High Performance Computing: 33rd International Conference, ISC High Performance 2018, Frankfurt, Germany, June 24-28, 2018, Proceedings, Springer, Cham, LNCS 10876, ISBN 978-3-319-92040-5 (2018), 22-43. DOI: 10.1007/978-3-319-92040-5_2, Preprint: arXiv:1803.01618. Winner of the ISC 2018 Gauss Award.
- M. Kreutzer, G. Hager, D. Ernst, H. Fehske, A.R. Bishop, and G. Wellein: Chebyshev Filter Diagonalization on Modern Manycore Processors and GPGPUs. In: R. Yokota, M. Weiland, D. Keyes, and C. Trinitis (eds.): High Performance Computing: 33rd International Conference, ISC High Performance 2018, Frankfurt, Germany, June 24-28, 2018, Proceedings, Springer, Cham, LNCS 10876, ISBN 978-3-319-92040-5 (2018), 329-349. DOI: 10.1007/978-3-319-92040-5_17. ISC 2018 Hans Meuer Award Finalist.
- M. Kreutzer, G. Hager, G. Wellein, H. Fehske, and A. R. Bishop: A unified sparse matrix data format for efficient general sparse matrix-vector multiplication on modern processors with wide SIMD units. SIAM Journal on Scientific Computing 36(5), C401–C423 (2014). DOI: 10.1137/130930352, Preprint: arXiv:1307.6209, BibTeX
Further information
- HPC Professorship Website: https://hpc.fau.de
- FAU University information system CRIS page